Local Augmentation for Graph Neural Networks
摘要
图神经网络(GNNs)在图相关任务上取得了显著的性能。GNNs的核心思想是通过聚合来自局部邻域的信息来获得信息丰富的表示。然而,对于邻居较少的节点,邻域信息是否得到充分聚合以学习表示仍然是一个开放问题。为了解决这个问题,我们提出了一种简单高效的数据增强策略——局部增强,来学习以中心节点表示为条件的邻居节点表示分布,并通过生成的特征增强GNN的表达能力。局部增强是一个通用框架,可以以即插即用的方式应用于任何GNN模型。它在每次训练迭代中从学习到的条件分布中采样与每个节点相关的特征向量,作为骨干模型的额外输入。广泛的实验和分析表明,当应用于各种GNN架构和多样化的基准测试时,局部增强始终能带来性能提升。例如,实验表明,将局部增强插入GCN和GAT中,在Cora、Citeseer和Pubmed上的测试准确率平均分别提高了3.4%和1.6%。此外,我们在大型图(OGB)上的实验结果表明,我们的模型相对于骨干网络始终能改善性能。代码可在 https://github.com/SongtaoLiu0823/LAGNN 获取。
note
传统的GNNs他就是依靠从直接邻居节点获取信息,但是这样就会有一个问题,万一有的节点只有一两个邻居,或者干脆没有邻居,那他从哪里获取信息呢,只有自身?那肯定不够,所以这会导致一些节点学习到的信息很少,不充分,这会使得模型整体拉胯起来,好像一颗老鼠屎坏了一锅汤。所以这篇文章就提出了一种新的方法,局部增强,传统的GNNs是依靠邻居,局部增强也是要依靠邻居,只是说他不但依靠直接真的邻居,也会依靠虚假的邻居(虚拟邻居)来获取信息,这样就可以解决一些节点没有很多邻居的问题了,但是这样肯定又有问题了,虚拟邻居怎么生成呢?我也不知道,需要往下看。
引言
图神经网络(GNNs)及其变体(Kipf & Welling, 2017; Hamilton et al., 2017; Veličković et al., 2018)在各种基于图的任务上取得了最先进的性能,包括推荐系统(Ying et al., 2018)、药物发现(Dai et al., 2019)和交通预测(Guo et al., 2019)。GNNs的核心是采用消息传递机制,传递和聚合来自局部邻域的信息以生成信息丰富的表示。深度GNNs的最新发展,如JKnet(Xu et al., 2018)、GCNII(Chen et al., 2020b)和RevGNNDeep(Li et al., 2021),通过残差式设计将浅层的输出添加到深层,以保留节点表示的局部信息(Chen et al., 2020b)。此外,最近的研究(Zeng et al., 2021; Zhang & Li, 2021; Wijesinghe & Wang, 2022)利用局部邻域的结构信息设计高效的消息传递聚合方案,以增强GNNs的表达能力。这些工作表明,局部信息在训练GNN模型和设计强大的GNNs中起着重要作用。
note
没有用残差的GNNs,这会导致一个问题,如果图有多层,那么经过多次的信息流动,越靠近刚开始初始层的信息越来越被淡化,后面层次所获取到的信息都逐渐平均化,大家的信息都快相同了,没有保留到各自特有的信息,残差就是来解决这个问题的,残差很简单的理解就是我这一层加上上一层的信息,这样可以保证每次都是new+old,即使不停的向上流动,第一层的信息依然可以被带到上层去,这样就可以解决平滑问题。
# 传统GNN:信息逐渐平均化
def traditional_gnn_problem():
# 第1层:每个节点还保留自己的特色
layer1 = {
"节点A": "原始特征A + 邻居1信息",
"节点B": "原始特征B + 邻居2信息",
"节点C": "原始特征C + 邻居3信息"
}
# 第2层:开始平均化
layer2 = {
"节点A": "平均化信息 + 更多邻居信息",
"节点B": "平均化信息 + 更多邻居信息",
"节点C": "平均化信息 + 更多邻居信息"
}
# 第3层:严重平均化
layer3 = {
"节点A": "几乎相同的全局信息",
"节点B": "几乎相同的全局信息", # 与A几乎一样
"节点C": "几乎相同的全局信息" # 与A、B几乎一样
}
# 结果:所有节点失去独特性!
# 残差GNN:new + old 保持独特性
def residual_gnn_solution():
# 第1层:new + old
layer1 = {
"节点A": "新学到的信息A + 原始特征A",
"节点B": "新学到的信息B + 原始特征B",
"节点C": "新学到的信息C + 原始特征C"
}
# 第2层:new + old(old包含了第1层的信息)
layer2 = {
"节点A": "新学到的信息A + 第1层信息A",
"节点B": "新学到的信息B + 第1层信息B",
"节点C": "新学到的信息C + 第1层信息C"
}
# 第3层:new + old(old包含了前面所有层的信息)
layer3 = {
"节点A": "新学到的信息A + 前面所有层信息A",
"节点B": "新学到的信息B + 前面所有层信息B",
"节点C": "新学到的信息C + 前面所有层信息C"
}
# 结果:每个节点都保持独特性!
尽管GNNs在从局部邻域学习节点表示方面取得了进展,但局部邻域信息是否足以获得有效的节点表示,特别是对于邻居数量有限的节点,仍然是一个开放问题。我们认为,局部邻域中有限的邻居数量限制了GNNs的表达能力并阻碍了它们的性能,特别是在样本稀缺的情况下,某些节点只有很少的邻居。堆叠图层以扩大感受野可以融入多跳邻域信息,但会导致过平滑(Li et al., 2018),而没有与输入的残差连接,这不是解决这个问题的直接方案。现有的GNN模型架构工作无法解决非常有限的邻居不利于学习节点表示的问题。因此,这里我们专注于丰富低度节点的局部信息以获得有效的表示。
note
什么是堆叠图层?堆叠图层浅显的从字面意思来讲,就是把一层堆在另一层上面,GNN有多层,我计算第二层就将第一层的输出作为输入,计算第三层,就将第二层的输出作为输入,注意,这里是上一层的输出作为输入,不是将上一层,所以每一层的输出都会在一定层度上修改了。
什么是感受野?感受野就是一个节点可以“看到”的其他节点的范围,就比如A有邻居B和C,A第一次是只能看到自己的直接邻居B和C的,看不到B和C的直接邻居的,但是扩大感受野就可以然A逐渐看到B和C的邻居,每次扩大,可以多看到一层邻居,这很像计算机网络中的一个算法,好像是洪水灌溉,那为啥会导致过平滑呢,很明显,后面的节点看到的都一样了,那各自的信息不就差不多了,平均化了,自然就过平滑了。详细可以看下面的代码
# 感受野 = 一个节点能够"看到"的其他节点的范围
def receptive_field():
# 第1层:每个节点只能看到直接邻居(1跳)
layer1_receptive_field = {
"节点A": ["邻居1", "邻居2"],
"节点B": ["邻居3", "邻居4", "邻居5"]
}
# 第2层:每个节点可以看到邻居的邻居(2跳)
layer2_receptive_field = {
"节点A": ["邻居1", "邻居2", "邻居1的邻居", "邻居2的邻居"],
"节点B": ["邻居3", "邻居4", "邻居5", "邻居3的邻居", "邻居4的邻居", "邻居5的邻居"]
}
# 第3层:每个节点可以看到3跳范围内的所有节点
layer3_receptive_field = {
"节点A": ["1跳邻居", "2跳邻居", "3跳邻居"],
"节点B": ["1跳邻居", "2跳邻居", "3跳邻居"]
}
# 过平滑现象
def over_smoothing_example():
# 初始状态:每个节点有独特特征
initial_features = {
"节点A": [1, 0, 0, 0], # 科技爱好者
"节点B": [0, 1, 0, 0], # 时尚达人
"节点C": [0, 0, 1, 0], # 运动爱好者
"节点D": [0, 0, 0, 1] # 美食家
}
# 第1层后:开始混合
layer1_features = {
"节点A": [0.7, 0.1, 0.1, 0.1],
"节点B": [0.1, 0.7, 0.1, 0.1],
"节点C": [0.1, 0.1, 0.7, 0.1],
"节点D": [0.1, 0.1, 0.1, 0.7]
}
# 第3层后:严重平均化
layer3_features = {
"节点A": [0.3, 0.3, 0.2, 0.2], # 失去独特性
"节点B": [0.3, 0.3, 0.2, 0.2], # 与A几乎相同
"节点C": [0.3, 0.3, 0.2, 0.2], # 与A、B几乎相同
"节点D": [0.3, 0.3, 0.2, 0.2] # 与A、B、C几乎相同
}
一个有前景的解决方案是通过数据增强在局部邻域中生成更多样本。数据增强在计算机视觉(Shorten & Khoshgoftaar, 2019; Cubuk et al., 2019; Zhao et al., 2019; Dong et al., 2022)和自然语言处理(Fadaee et al., 2017; Şahin & Steedman, 2019; Xia et al., 2019)中得到了充分研究,但在图结构数据上仍然探索不足。现有的图数据增强方法只从全局角度在拓扑级别和特征级别进行扰动,可以分为两类:拓扑级别增强(Rong et al., 2020; Zhao et al., 2021)和特征级别增强(Deng et al., 2019; Feng et al., 2019; Kong et al., 2020; Fang et al., 2021)。拓扑级别增强扰动邻接矩阵,产生不同的图结构。另一方面,现有的特征级别增强(Deng et al., 2019; Feng et al., 2019; Kong et al., 2020)利用对抗训练指导的节点属性扰动来提升泛化能力。这些增强技术有一个突出的缺点:它们专注于关于整个图分布属性的全局增强,而不是单个节点,忽略了邻域的局部信息。
当前工作。在这项工作中,为了通过局部邻域中更多生成的样本来促进聚合方案,我们提出了一个新颖高效的数据增强框架:图神经网络的局部增强(LA-GNNs)。术语”局部增强”指的是通过以局部结构和节点特征为条件的生成模型生成邻域特征。具体来说,我们提出的框架包括一个预训练步骤,该步骤通过生成模型学习给定一个中心节点特征的连接邻居节点特征的条件分布。如图1所示,我们然后利用这个分布在每次训练迭代中生成与此中心节点相关的特征向量作为额外输入。此外,我们将生成模型的预训练和下游GNN训练解耦,允许我们的数据增强模型以即插即用的方式应用于任何GNN模型。
我们在三个标准引用网络(Cora、Citeseer、Pubmed)和开放图基准(OGB)(Hu et al., 2020)上验证了LA-GNNs的有效性。半监督节点分类的广泛实验结果表明,我们的局部增强实现了新的最先进性能:LAGCN和LAGAT在Cora、Citeseer和Pubmed上分别比GCN和GAT平均提高了3.4%和1.6%的测试准确率。LAGNN在大规模OGB数据集上也获得了优越的性能。我们表明,我们的模型在Pubmed上对于度在[2,5]和[6,20]范围内的节点分别提高了1.7%和0.2%的测试准确率。此外,我们的局部增强模型在节点分类任务上优于其他特征/拓扑级别增强模型,如G-GNN(Zhu et al., 2020)、DropEdge(Rong et al., 2020)、GRAND(Feng et al., 2020)和GAUG(Zhao et al., 2021),这证明了我们模型的优越性。
贡献:
- 我们提出了一种通用的增强策略,在局部邻域中生成更多特征以增强现有GNNs的表达能力;
- 我们探索了为图预训练生成模型以提高下游任务性能的新方向;
- 我们提出的框架是灵活的,可以应用于各种流行的骨干网络。广泛的实验结果表明,我们提出的框架可以改善GNN变体在不同基准数据集上的性能。
2. 预备知识
符号表示
设 表示图,其中 是顶点集合 ,, 是边集合。邻接矩阵定义为 ,当且仅当 时 。设 表示节点 的邻域, 表示对角度矩阵,其中 。特征矩阵表示为 ,其中每个节点 与一个 维特征向量 相关联。 表示独热标签矩阵,其中 是独热向量,对于任何 ,。
note
什么是独热向量?什么是独热矩阵?独热独热,字面上来看就是唯独他是热的,计算机里都是0,1,0,1,所以独热向量,就是一个向量中,只有一个元素是1,其他元素都是0,可以看下面的例子:
# 假设有4个类别:科技、时尚、运动、美食
# 独热向量示例
tech_vector = [1, 0, 0, 0] # 科技类别
fashion_vector = [0, 1, 0, 0] # 时尚类别
sports_vector = [0, 0, 1, 0] # 运动类别
food_vector = [0, 0, 0, 1] # 美食类别
# 特点:
# 1. 只有一个位置是1
# 2. 其他位置都是0
# 3. 所有元素的和等于1
那独热矩阵就好理解了,就是由多个独热向量构成的矩阵嘛
# 假设有4个用户,3个类别:科技爱好者、时尚达人、运动爱好者
label_matrix = [
[1, 0, 0], # 用户1: 科技爱好者
[0, 1, 0], # 用户2: 时尚达人
[0, 0, 1], # 用户3: 运动爱好者
[1, 0, 0] # 用户4: 科技爱好者
]
# 矩阵形状: 4×3 (4个节点,3个类别)
图神经网络
许多流行的图神经网络(GNNs)直接在图结构上操作,并通过图中节点之间的消息传递来捕获图的依赖性。它们重复聚合节点 的直接邻居 的表示,并将聚合的信息与其表示向量结合以获得表示向量 。GNN消息传递方案的第 层是:
其中 和 分别表示COMBINE和AGGREGATE函数, 是节点 在第 层的表示向量, 是节点 和 之间的边向量。具体地,。
note
AGG表示聚合函数AGGREGAT,聚合聚合就是将多个向量合成一个,比如当前中心节点有三个邻居向量A[1,2,3],B[2,3,4],C[3,4,5],那么AGG([A,B,C]) = [1+2+3,2+3+4,3+4+5] ( 假设是求和聚合) ,常见的聚合还有最大值聚合,注意力聚合,注意力聚合更像是加权聚合一样的,可能我理解的有误。
COMBINE函数的作用是将节点自身的信息与聚合的邻居信息结合起来,生成新的节点表示。那COMBINE如何将不同信息结合起来呢,我查了一下,这里有一些常见的,如拼接+线性变换,加权平均,门控机制,残差连接等等,具体可以看下面的代码:
def concat_combine(self_info, neighbor_info):
# 拼接自身信息和邻居信息
combined = concatenate(self_info, neighbor_info)
# combined = [1, 0, 0, 0, 0.5, 0.5]
# 通过线性变换降维
output = linear_transform(combined)
# output = [0.7, 0.2, 0.1] # 新的表示
return output
def weighted_combine(self_info, neighbor_info, alpha=0.5):
# 加权结合自身信息和邻居信息
output = alpha * self_info + (1 - alpha) * neighbor_info
return output
def gated_combine(self_info, neighbor_info):
# 学习一个门控向量,决定保留多少自身信息
gate = sigmoid(linear_transform(self_info + neighbor_info))
# 门控结合
output = gate * self_info + (1 - gate) * neighbor_info
return output
def residual_combine(self_info, neighbor_info):
# 残差连接:自身信息 + 邻居信息
output = self_info + neighbor_info
return output
那公式是什么意思呢,公式就是表示计算节点v在第k层的表示 = COMBINE(v在第k-1层的表示,AGG(所有邻居节点在k-1层的表示)),看下面的例子就会清楚很多了:
def gnn_layer_computation():
# 假设节点v有3个邻居:u1, u2, u3
# 输入
h_v_prev = [1, 0, 0] # 节点v上一层的表示
h_u1_prev = [0, 1, 0] # 邻居u1上一层的表示
h_u2_prev = [0, 0, 1] # 邻居u2上一层的表示
h_u3_prev = [1, 1, 0] # 邻居u3上一层的表示
# 步骤1:聚合邻居信息
neighbor_features = [h_u1_prev, h_u2_prev, h_u3_prev]
aggregated = mean_aggregate(neighbor_features) # 假设使用平均聚合
# aggregated = [0.33, 0.67, 0.33]
# 步骤2:组合自身信息和聚合信息
h_v_new = combine(h_v_prev, aggregated)
# h_v_new = [0.67, 0.33, 0.17] # 新的表示
return h_v_new
图神经网络的局部增强(LAGNN)
在本节中,我们首先介绍如何通过生成模型在局部邻域中生成更多样本。然后我们从概率角度展示如何解耦生成模型的预训练和下游GNN训练,使得我们的局部增强模型可以以即插即用的方式应用于任何GNN模型。接着我们介绍LA-GNNs的架构和训练细节。整体框架如图1所示。

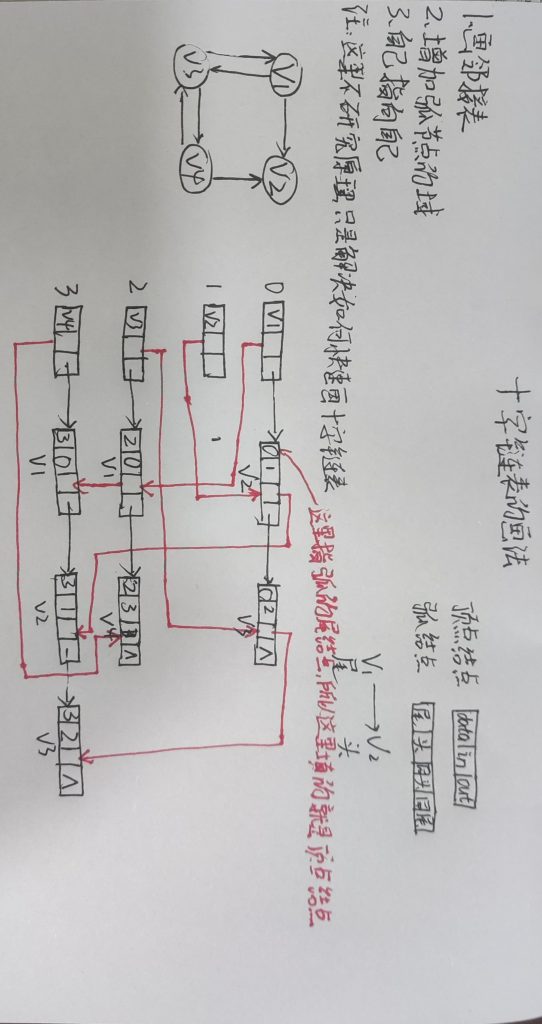
图1. 我们局部增强的示意图。图上的黄色圆圈对应邻居节点。假设我们已经学习了局部邻域的分布。我们从局部邻域分布生成特征。然后我们将原始特征和生成的特征作为下游GNNs的输入。
note
这张图中选了五个不同颜色的点,假设这几个点的邻居比较少,信息不足,所以我们要采取局部增强,为这五个不同颜色的点添加虚拟邻居,图中左上方就是表示原始这五个点的特征向量,然后左下方的图就是表示对这五个节点进行生成虚拟邻居的操作,每个节点生成一定数量的虚拟邻居,黄色节点就是表示虚拟邻居,然后再将真实的特征向量与生成的虚拟特征向量进行结合,一起传递给下游的GNN训练,这张图就是阐述了LAGNN的核心思想。
3.1. 局部增强动机
现有的GNNs专注于设计消息传递方案来利用局部信息以获得节点表示。我们探索了一个新方向,即我们可以在局部邻域中生成更多样本,特别是对于邻居较少的节点,以增强各种GNNs的表达能力。为了在节点v的邻域中产生更多样本,我们需要知道其邻居节点表示的概率分布。由于这个分布与中心节点v相关,我们可以通过生成模型以中心节点的表示为条件来学习它。
优势。与为每个节点训练生成模型相比,为所有节点训练单个生成模型有三个优势:1)通过生成模型学习图中所有节点的条件分布降低了计算成本。2)在生成阶段,我们可以应用特定节点的特征向量作为输入(条件)并生成与此节点相关的特征向量。3)它具有更好的可扩展性和泛化性。对于添加到动态图中的新节点,我们可以直接生成特征向量而无需重新训练新的生成模型,因为生成模型包含这种泛化信息。因此我们的局部增强模型可以应用于归纳学习任务,如图分类。
note
第一个优势在于他技术选择上,在生成模型中,不是给每个中心节点都创建一个训练模型,而是训练一个统一的模型,我刚开始理解错了,以为是传统GNN VS LAGNN,结果问AI说是上面的意思。 第二个优势就是,他是利用中心节点生成虚拟特征向量用与学习,他这里分为了两个阶段,第一个阶段是预训练阶段,是将图真实的信息,即各个中心节点,真实的邻居分布用与训练;第二个阶段,就是使用虚拟邻居增强GNN,这时候,预训练的模型是知道此中心节点的邻居分布的,然后再根据自身的特征向量进行生成,虚拟邻居的诞生其实是“参考”了邻居的。第三个优势就是当图中加入了新的节点时,模型既可以将新节点的特征向量加入训练,也可以生成虚拟邻居特征向量,这样会更丰富,而传统的GNN只能将新节点的特征向量和邻居信息加入训练,这样可能会不够准确。
方法。我们利用条件变分自编码器(CVAE)(Kingma & Welling, 2013; Sohn et al., 2015)来学习给定中心节点v的连接邻居u(u ∈ )的节点特征的条件分布。在我们的CVAE设置中,我们使用作为条件,因为(u ∈ )的分布与相关。遵循Sohn et al. (2015),潜在变量z从先验分布(z|)生成,数据通过以z和为条件的生成分布(X|, z)生成:z ∼ pθ(z|), ∼ (X|, zv)。设φ表示变分参数,θ表示生成参数,我们有:
证据下界(ELBO)可以写为:
其中z^(l) = gφ(, , ε(l)),ε(l) ∼ N(0, I),L是节点v的邻居数量。注意,正如我们之前讨论的,我们只为所有节点训练一个CVAE。在训练阶段,目标是使用邻居对(, , u ∈)作为输入来最大化ELBO,即方程(2)。在生成阶段,我们使用节点特征Xv作为条件,并采样潜在变量z ∼ N(0, I)作为解码器的输入。然后我们可以得到与节点v相关的生成特征向量Xv。
note
什么是KL散度,KL散度是衡量两个概率分布之间的差异的度量,就是说这两个概率之间的“距离”问题,他们相似度,你和我长的像吗?KL值越小表示分布之间越相似,你我长得挺像;KL值越大表示分布之间越不同,你和我长得很不一样。
先看一下证据下界这个公式,他分为两个部分,前半部分是KL散度的负数,他是希望KL散度越小,则-KL就越大,KL散度越小,表示编码器输出的分布与先验分布之间的相似程度越大,这正是我们想要的结果,后半部分是指当前中心节点的不同邻居生成邻居特征的质量评估,数值越高,表示特征质量越好。
再看一下上面的公式,上面的公式其实前半部分就是下界ELBO,只是上面是理论公式,需要使用复杂的积分,这难以实现,而下面是我们实际代码中实现的结果,两者是等价的,这个公式是变分推理的核心,它告诉我们无法计算的目标可以用可计算的下界来近似,通过最大化下界,我们可以间接最大化真实目标。
讨论。在学习以中心节点为条件的邻居特征分布时,我们没有考虑连接到每个邻居的其他节点对邻居特征的影响。如果我们将中心节点视为父节点,将其邻居视为中心节点的子节点,那么我们的假设类似于贝叶斯网络中的因果马尔可夫条件(Hausman & Woodward, 1999):给定其父节点,邻居特征的分布与其非后代节点独立。这个假设在概率图模型的文献中是重要且常见的。优势是这个假设避免了对多跳邻居条件的指数复杂度,显著提高了可扩展性。我们的实验结果表明,由于深度生成模型的表达能力(类似于变分推理的假设在真实数据集中不限制深度VAEs的性能),我们的方法在所有基准测试中仍然取得了显著的性能。
note
什么是贝叶斯网络,贝叶斯网络结构就是很常见的网络结构,就是父节点->子节点->孙节点这种结构,这让我想到了二叉树。然后贝叶斯网络中的因果马尔代夫条件就是说,子节点的孙节点对子节点没有影响,对子节点有影响的只有父节点,假设有A->B->C, B的特征只会受A影响,C不会对B的特征产生影响。那为什么在LAGNN中使用这种假设呢,因为很明显,在一张图中,一个节点可能会有多个邻居,邻居就相当于有父子关系,如果我们考虑所有节点之间的影响,那么付出对应的代价会很大,所以我们要做出这种假设,只有父节点对子节点有影响,而孙节点对子节点没有影响,这样会减少很多的麻烦。
3.2. 将生成模型训练与下游图学习解耦
大多数现有的GNN模型遵循消息传递机制(Gilmer et al., 2017),可以被视为学习到的分类或回归函数。为了进行预测,GNN模型需要估计关于图结构A和特征矩阵X的后验分布PΘ(·|A, X)。例如,·可以是节点分类任务上的类别标签Y。我们可以使用最大似然估计(MLE)通过优化以下似然函数来估计参数Θ:
其中i表示训练数据集中的第i个数据点。在我们的局部增强模型中,为了进一步提高GNNs的表达能力,我们通过使用Xv作为输入条件并从生成模型中采样,为中心节点v引入一个生成的特征向量Xv。设X表示生成的特征矩阵,其中第j行对应于生成的特征向量Xj。我们将X纳入方程(3)并重写如下:
为了贝叶斯可处理性,我们将方程(4)中的PΘ分解为两个后验概率的乘积:
其中PΘ(·|A, X, X)和QΦ(X|A, X)分别表示由GNN模型和生成模型近似的概率分布,分别由Θ和Φ参数化。通过这样做,我们可以解耦我们提出的局部增强和特定的图学习,允许我们的增强模型应用于各种GNN模型,而生成模型只需要一次预训练。因此,局部增强可以被视为GNN训练之前的无监督预训练模型。方程(5)的表示能力优于单个预测器PΘ(Yk|A, X),因为我们在局部邻域中为GNN模型提供了更多生成的样本。
note
上面的公式看着真的头晕,但是透过现象看本质,第一个公式就是说传统GNN他只会直接训练GNN,使用原始特征,而第二个公式表示,引入了生成特征,第三个公式就是LAGNN的原理,分解训练,表示生成虚拟邻居特征,表示将所有的信息用与训练GNN模型。
3.3. 架构
在本节中,我们详细介绍如何使用来自我们局部增强模型的生成样本作为额外输入来训练GNNs。为了说明我们局部增强模型的有效性,我们提供了两种不同的利用生成样本的方式,导致了架构的平均和拼接设计。
LAGCN。对于GCN,我们只对第一个图卷积层进行小幅修改:
其中 。符号 表示在第二维度上拼接矩阵。权重矩阵W中的下标和上标分别表示层的序号和参数的序号。为了不改变GCN模型的参数大小, 和 的第二维度之和等于GCN的 的第二维度。对于其他架构(LAGAT、LASAGE、LAGCNII),我们将在后面讨论,我们在第一层保持与LAGCN相同的参数大小设置。对于GraphSAGE和GCNII,它们具有与GCN相似的架构,我们对LASAGE和LAGCNII采用与LAGCN相同的修改策略。除了拼接式设计外,我们还可以平均X和X作为GNNs的输入,而不改变架构。
LAGAT。类似地,LAGAT的第一层定义如下:
其中 在X上计算()或在X上计算()。注意 的第二维度与GAT相同。我们只是将一半注意力头的输入替换为X。我们也为GAT提供了平均式设计。
3.4. 损失函数
在本节中,我们解释训练LAGNNs的两种损失函数及其潜在动机:监督损失和一致性损失。
监督损失。一旦我们完成了局部增强模型的预训练,我们就使用它产生的生成特征矩阵X作为额外输入来增强GNN模型的表达能力。给定训练标签K和S个增强特征矩阵X^(s),我们可以将节点分类任务的监督损失函数写为:
其中 。注意我们只提供了一种监督损失函数。对于其他图学习任务,如链接预测和图分类,监督损失函数可以相应调整。
一致性正则化损失。受到一致性训练在半监督学习任务上巨大成功的启发(Wang et al., 2020c; Feng et al., 2020; Sajjadi et al., 2016; Samuli & Timo, 2017; Berthelot et al., 2019; Verma et al., 2019),我们为特定的GNNs和图学习任务提供了一个可选的损失函数。直观上,一致性正则化鼓励在每个训练迭代中对不同输入的不变预测(Verma et al., 2019)。具体地,一致性正则化损失函数具有以下形式:
其中 , 是锐化技巧(Berthelot et al., 2019),T是调整这个分类分布”温度”的超参数。锐化技巧可以减少预测的熵。
训练和推理。我们训练和推理过程的细节在算法1中概述。首先,我们训练CVAE,即我们的局部增强模型。然后我们在每个训练迭代中采样由CVAE生成的不同特征矩阵作为额外输入来训练GNN模型。但对于GRAND(Feng et al., 2020),我们在训练阶段只采样一个特征矩阵,因为我们发现使用这样的采样策略可以获得更好的性能。监督损失函数在初始特征矩阵X和生成特征矩阵X上计算。此外,我们可选地基于为特定任务计算一致性正则化损失函数。此外,我们在每个训练迭代中重新采样另一个与计算训练损失函数不同的特征矩阵来计算验证损失函数和验证准确率。在推理阶段,我们不需要再次生成X,因为我们在引用数据集(Cora、Citeseer、Pubmed)上选择具有最小验证损失函数的X,或在OGB数据集上选择具有最高验证准确率的X。预训练和GNN训练的计算复杂度分别为和,其中D是隐藏通道数,L是层数。预训练轮数通常少于10轮,这表明预训练引入的计算开销很小。
note
LAGNN的两种损失分别代表啥呢?损失首先表示的是真实值与预测值的差距,这是我的理解,在GNN中,你会训练一个模型,然后用这个模型预测出一些输出,这些输出与使用输入得出的真实输出的差距就是损失,损失就是衡量标签与预测之间的差距。然后监督损失表示的就是模型分类的效果,让模型可以比较预测结果和真实标签,让模型学会正确分类,损失太大,表示模型学的分类效果不好,损失小则好。一致性损失是为了增强模型,使用虚拟邻居特征来增强模型,让模型预测的水平更高,更稳定,这里的核心就是通过虚拟邻居特征来增强模型了。
训练和推理
我们训练和推理过程的细节在算法1中概述。首先,我们训练CVAE,即我们的局部增强模型。然后我们在每个训练迭代中采样由CVAE生成的不同特征矩阵作为额外输入来训练GNN模型。但对于GRAND(Feng et al., 2020),我们在训练阶段只采样一个特征矩阵,因为我们发现使用这样的采样策略可以获得更好的性能。
监督损失函数在初始特征矩阵X和生成特征矩阵X上计算。此外,我们可选地基于fLAGNN(A, X, X^(s), Θ)为特定任务计算一致性正则化损失函数L_con。此外,我们在每个训练迭代中重新采样另一个与计算训练损失函数不同的特征矩阵来计算验证损失函数和验证准确率。
在推理阶段,我们不需要再次生成X,因为我们在引用数据集(Cora、Citeseer、Pubmed)上选择具有最小验证损失函数的X,或在OGB数据集上选择具有最高验证准确率的X。
预训练和GNN训练的计算复杂度分别为O(|E|(FD + LD²))和O(S|E|(FD + LD²)),其中D是隐藏通道数,L是层数。预训练轮数通常少于10轮,这表明预训练引入的计算开销很小。
算法1 图神经网络的局部增强
- 输入:邻接矩阵A,特征矩阵X
- 输出:预测Z
- 使用方程(2)预训练生成模型,给定A和X作为输入
- while 未收敛 do
- for s = 1 : S do
- 生成增强特征矩阵:
- 使用LAGNN 获得预测:
- end for
- 通过方程(8)计算监督分类损失
- 可选地通过方程(9)计算一致性正则化损失
- 通过梯度下降更新参数Θ:
- 重新生成增强特征矩阵:
- 通过和方程(8)计算验证损失函数或验证准确率
- end while
- 通过进行预测,其中我们选择具有最小验证损失函数或最高验证准确率的X
表1. 三个引用网络上的分类结果(%)
| 方法 | Cora | Citeseer | Pubmed |
|---|---|---|---|
| Chebyshev | 81.2 | 69.8 | 74.4 |
| APPNP | 83.8±0.3 | 71.6±0.5 | 79.7±0.3 |
| MixHop | 81.9±0.4 | 71.4±0.8 | 80.8±0.6 |
| Graph U-net | 84.4±0.6 | 73.2±0.5 | 79.6±0.2 |
| GSNN-M | 83.9±0.5 | 72.2±0.5 | 79.1±0.3 |
| S2GC | 83.5±0.02 | 73.6±0.09 | 80.2±0.02 |
| GCN | 81.5±0.5 | 70.3±0.7 | 79.0±0.5 |
| G-GCN | 83.7 | 71.3 | 80.9 |
| DropEdge-GCN | 82.8 | 72.3 | 79.6 |
| GAUG-O-GCN | 83.6±0.5 | 73.3±1.1 | 79.3±0.4 |
| GraphSNNGCN | 83.1±1.8 | 72.3±1.5 | 79.8±1.2 |
| GRAND-GCN | 84.5±0.3 | 74.2±0.3 | 80.0±0.3 |
| LA-GCN | 84.6±0.5 | 74.7±0.5 | 81.7±0.7 |
| GAT | 83.0±0.7 | 72.5±0.7 | 79.0±0.3 |
| GAUG-O-GAT | 82.2±0.2 | 71.6±1.1 | OOM |
| GraphSNNGAT | 83.8±1.2 | 73.5±1.6 | 79.6±1.4 |
| GRAND-GAT | 84.3±0.4 | 73.2±0.4 | 79.2±0.6 |
| LA-GAT | 84.7±0.4 | 73.7±0.5 | 81.0±0.4 |
| GCNII | 85.5±0.5 | 73.4±0.6 | 80.2±0.4 |
| LA-GCNII | 85.7±0.3 | 74.1±0.5 | 80.6±0.7 |
| GRAND | 85.4±0.4 | 75.4±0.4 | 82.7±0.6 |
| LA-GRAND | 85.7±0.3 | 75.8±0.5 | 83.4±0.6 |
4. 实验
在本节中,我们评估了我们的局部增强模型在各种任务上的性能,包括节点分类、链接预测和图分类。所有实验都在开放图数据集上进行。
4.1. 半监督学习
数据集。我们利用三个公共引用网络数据集Cora、Citeseer和Pubmed(Sen et al., 2008)进行半监督节点分类。所有数据集的统计信息可以在附录D中找到。
基线模型。我们考虑三种流行的图神经网络:GCN(Kipf & Welling, 2017)、GAT(Veličković et al., 2018)和GCNII(Chen et al., 2020b)作为我们实现的骨干网络。GCN和GAT是最先进GNN架构的代表,而GCNII是具有跳跃连接设计的深度GNN模型。对于这些骨干网络中的每一个,我们采用第3.3节中讨论的拼接式设计作为我们的LAGNN架构。但我们保持LAGNN的可学习权重矩阵大小与相应的GNN模型相同,这在附录D中有详细说明。我们还将我们的方法与其他数据增强模型——GRAND(Feng et al., 2020)结合。为了评估我们提出的框架,我们将我们的模型与四类最先进的模型进行比较:
- 骨干模型:Chebyshev(Defferrard et al., 2016)、GCN(Kipf & Welling, 2017)、GAT(Veličković et al., 2018)、APPNP(Klicpera et al., 2019)、Graph U-net(Gao & Ji, 2019)、MixHop(Abu-El-Haija et al., 2019)、GCNII(Chen et al., 2020b)、GSNN-M(Wang et al., 2020a)和S2GC(Zhu & Koniusz, 2021)
- 特征级增强模型:G-GNNs(Zhu et al., 2020)和GRAND(Feng et al., 2020)
- 拓扑级增强模型:DropEdge(Rong et al., 2020)和GAUG-O(Zhao et al., 2021)
- 子图GNN:GraphSNN(Wijesinghe & Wang, 2022)
基线模型的选择旨在表明现有的GNNs从我们提出的局部数据增强中受益,并且我们的模型优于其他数据增强模型。
实验设置。我们在Cora、Citeseer和Pubmed上应用标准固定分割(Yang et al., 2016),每个类别20个节点用于训练,500个节点用于验证,1000个节点用于测试。更多关于实验设置和超参数的详细信息请参见附录D。
与SOTA的比较。我们在表1中报告了100次运行后的平均节点分类准确率。我们重用了相应论文中已报告的基线指标。结果表明,配备我们方法的骨干模型在所有三个数据集上都取得了更好的性能。具体地,局部增强可以在Cora、Citeseer和Pubmed上分别比GCN提高3.1%、4.4%和2.7%,而LAGAT相比GAT的改进幅度分别为1.7%、1.2%和2.0%。此外,当与其他数据增强方法——GRAND结合时,我们仍然可以分别提高0.3%、0.4%和0.7%。此外,基于GRAND和我们的LA-GRAND实验结果的标准差信息,我们通过t检验计算p值来验证改进。除了LA-GCN与GRAND-GCN在Cora上的比较(p值为0.046)外,所有p值都≪0.01(GRAND也采用了相同的测试),这表明LA相比GRAND的改进在统计上是显著的。
与其他数据增强模型(Zhu et al., 2020; Rong et al., 2020; Zhao et al., 2021)相比,LA-GNN在两个流行的骨干网络GCN和GAT上取得了最佳性能,表明从全局角度来看,局部信息确实优于增强方法,如DropEdge(Rong et al., 2020)和GAUG(Zhao et al., 2021)。我们的模型和GraphSNN都从子图的角度出发。结果表明,局部增强在捕获局部邻域的特征信息方面比GraphSNN更有效,这证明了在设计子图相关的GNNs时考虑特征和结构信息更好。
表2. 节点属性预测的测试性能(%),平均10次运行
| 模型 | products Acc | proteins ROC-AUC | arxiv Acc |
|---|---|---|---|
| MLP | 61.06±0.08 | 72.04±0.48 | 55.50±0.23 |
| CoLinkDistMLP | 62.59±0.10 | – | 56.38±0.16 |
| Node2vec | 72.49±0.10 | 68.81±0.65 | 70.07±0.13 |
| GraphZoom | 74.06±0.26 | – | 71.18±0.18 |
| GCN | 75.64±0.21 | 72.51±0.35 | 71.74±0.29 |
| +FLAG | – | 71.71±0.50 | 72.04±0.20 |
| +GraphSNN | – | – | 72.20±0.90 |
| +LA | 76.11±0.09 | 73.25±0.51 | 72.08±0.14 |
| GraphSAGE | 78.70±0.36 | 77.68±0.20 | 71.49±0.27 |
| +FLAG | 79.36±0.57 | 76.57±0.75 | 72.19±0.21 |
| +GraphSNN | – | – | 71.80±0.70 |
| +LA | 79.44±0.25 | 77.86±0.37 | 72.30±0.12 |
| GAT | 79.45±0.59 | – | 73.65±0.11 |
| +FLAG | 81.76±0.45 | – | 73.71±0.13 |
| +LA | 80.46±0.54 | – | 73.77±0.12 |
表3. 链接预测的测试性能(%),平均10次运行
| 模型 | ogbl-collab Hits@50 (%) |
|---|---|
| MLP | 19.27±1.29 |
| Node2vec | 48.88±0.54 |
| GCN | 44.75±1.07 |
| +LA | 47.49±1.40 |
| GraphSAGE | 48.10±0.81 |
| +LA | 49.23±0.55 |
表4. 图属性预测的测试性能(%),平均10次运行
| 模型 | ogbg-molhiv ROC-AUC | ogbg-molpcba AP |
|---|---|---|
| GCN | 76.06±0.97 | 20.20±0.24 |
| +LA | 76.18±1.11 | 20.28±0.16 |
| GIN | 75.58±1.40 | 22.66±0.28 |
| +LA | 75.20±1.74 | 22.38±0.24 |
4.2. 全监督学习
数据集。为了证明我们的模型在大型图上的全监督节点和链接分类任务中的有效性,我们利用来自Open Graph Benchmark (OGB)(Hu et al., 2020)的ogbn-products、ogbn-proteins、ogbn-arxiv和ogbl-collab数据集进行评估。所有数据集的统计信息可以在附录D中找到。
基线模型。我们考虑四种流行的消息传递GNNs:GCN(Kipf & Welling, 2017)、GAT(Veličković et al., 2018)和GraphSAGE(Hamilton et al., 2017)作为骨干网络。对于这些骨干网络中的每一个,我们应用第3.3节中讨论的拼接式或平均式设计作为我们的LAGNN架构,这在附录D中有详细说明。对于arxiv、proteins和products上的节点分类,我们将其与MLP、Node2vec(Grover & Leskovec, 2016)、GCN、GAT、GraphSAGE、FLAG(Kong et al., 2020)、GraphSNN(Wijesinghe & Wang, 2022)、GraphZoom(Deng et al., 2020)和CoLinkDistMLP(Luo et al., 2021)进行比较。此外,我们使用ogbl-collab来评估我们的模型在链接预测任务上的性能,并将其与MLP、Node2vec、GCN、GraphSAGE进行比较。
实验设置和结果。我们遵循OGB(Hu et al., 2020)中的实验设置。对于详细设置,如分割比例和评估指标,我们只是遵循OGB实现中的相同设置。注意,基线模型的测试结果来自官方OGB排行榜网站或相应论文。为了公平比较,我们在OGB任务上从开源代码实现我们的模型,只修改第一层。从OGB排行榜可以看出,测试结果对模型大小和各种技巧都很敏感。因此,我们按照第3.3节的建议不改变骨干网络的模型大小,也不添加其他技巧。我们LAGNN架构的详细信息可以在附录D中找到。结果总结在表2和表3中。遵循常见做法,我们报告与最佳验证性能相关的测试准确率。节点和链接预测的结果表明,我们的增强模型在骨干网络上持续改进了性能。
主要发现:
- 节点分类任务:
- 在ogbn-products数据集上,LA方法在所有GNN变体上都取得了最佳性能
- 在ogbn-proteins数据集上,LA方法显著提升了ROC-AUC分数
- 在ogbn-arxiv数据集上,LA方法在GraphSAGE上取得了最佳性能
- 链接预测任务:
- 在ogbl-collab数据集上,LA方法在GCN和GraphSAGE上都取得了显著的性能提升
- LA-GraphSAGE达到了最高的Hits@50分数(49.23%)
- 方法的一致性:
- LA方法在所有测试的大型图数据集上都表现出一致的改进
- 证明了局部增强方法在不同规模和类型的图上的有效性和通用性
这些结果进一步验证了局部增强方法在大规模图学习任务中的有效性和鲁棒性。
表2. 节点属性预测的测试性能(%),平均10次运行
| 模型 | products Acc | proteins ROC-AUC | arxiv Acc |
|---|---|---|---|
| MLP | 61.06±0.08 | 72.04±0.48 | 55.50±0.23 |
| CoLinkDistMLP | 62.59±0.10 | – | 56.38±0.16 |
| Node2vec | 72.49±0.10 | 68.81±0.65 | 70.07±0.13 |
| GraphZoom | 74.06±0.26 | – | 71.18±0.18 |
| GCN | 75.64±0.21 | 72.51±0.35 | 71.74±0.29 |
| +FLAG | – | 71.71±0.50 | 72.04±0.20 |
| +GraphSNN | – | – | 72.20±0.90 |
| +LA | 76.11±0.09 | 73.25±0.51 | 72.08±0.14 |
| GraphSAGE | 78.70±0.36 | 77.68±0.20 | 71.49±0.27 |
| +FLAG | 79.36±0.57 | 76.57±0.75 | 72.19±0.21 |
| +GraphSNN | – | – | 71.80±0.70 |
| +LA | 79.44±0.25 | 77.86±0.37 | 72.30±0.12 |
| GAT | 79.45±0.59 | – | 73.65±0.11 |
| +FLAG | 81.76±0.45 | – | 73.71±0.13 |
| +LA | 80.46±0.54 | – | 73.77±0.12 |
表3. 链接预测的测试性能(%),平均10次运行
| 模型 | ogbl-collab Hits@50 (%) |
|---|---|
| MLP | 19.27±1.29 |
| Node2vec | 48.88±0.54 |
| GCN | 44.75±1.07 |
| +LA | 47.49±1.40 |
| GraphSAGE | 48.10±0.81 |
| +LA | 49.23±0.55 |
表4. 图属性预测的测试性能(%),平均10次运行
| 模型 | ogbg-molhiv ROC-AUC | ogbg-molpcba AP |
|---|---|---|
| GCN | 76.06±0.97 | 20.20±0.24 |
| +LA | 76.18±1.11 | 20.28±0.16 |
| GIN | 75.58±1.40 | 22.66±0.28 |
| +LA | 75.20±1.74 | 22.38±0.24 |
4.3. 归纳学习
为了评估我们的模型在归纳学习任务上的有效性,我们使用来自OGB的ogbg-molhiv和ogbg-molpcba数据集进行评估。对于实验设置,我们遵循官方OGB实现。我们考虑GCN和GIN(Xu et al., 2019b)作为骨干网络,LAGCN和LAGIN的架构可以在附录D中找到。结果总结在表4中。
实验结果表明,我们的模型在归纳学习任务上仍然适用于GCN。我们的生成模型只在训练数据集上进行训练。只要测试数据集和训练数据集上的图具有相似的分布,即相似的子图结构和特征向量,我们的生成模型就可以做出合理的推理并生成有效的增强特征向量。
主要发现:
- 归纳学习能力:
- LA方法在GCN上取得了小幅但一致的改进
- 在ogbg-molhiv数据集上:LA-GCN (76.18%) vs GCN (76.06%)
- 在ogbg-molpcba数据集上:LA-GCN (20.28%) vs GCN (20.20%)
- 泛化能力:
- 生成模型只在训练数据上训练,但能在测试数据上有效工作
- 证明了局部增强方法具有良好的泛化能力
表5. 在Pubmed数据集上评估的LAGCN不同组件的效果
| 技术 | 准确率 (%) | ∆ | 累积∆ |
|---|---|---|---|
| GCN | 79.0 | 0 | 0 |
| + Concatenation | 79.3±0.4 | 0.3 | 0.3 |
| + Local Augmentation | 81.1±0.5 | 1.8 | 2.1 |
| + Consistency Training | 81.4±0.5 | 0.3 | 2.4 |
| + Sharpening Trick | 81.7±0.7 | 0.3 | 2.7 |
消融研究分析:
- 架构修改贡献:仅拼接原始特征带来0.3%的提升
- 局部增强核心贡献:生成特征矩阵带来1.8%的显著提升
- 一致性训练贡献:额外0.3%的提升
- 锐化技巧贡献:最终0.3%的提升
- 总体提升:从79.0%提升到81.7%,总共2.7%的改进
表6. 在Citeseer数据集上特征恢复研究的GCN结果总结(分类准确率%)
| 屏蔽比例 | 0.1 | 0.2 | 0.4 | 0.8 |
|---|---|---|---|---|
| GCN | 70.4(↑0.1) | 69.2(↓1.1) | 67.2(↓3.1) | 61.1(↓9.2) |
| LAGCN | 73.8(↓0.9) | 74.0(↓0.7) | 71.8(↓2.9) | 68.7(↓6.0) |
鲁棒性分析:
- 低屏蔽比例(0.1-0.2):
- GCN性能基本保持或略有下降
- LAGCN性能略有下降但保持较高水平
- 高屏蔽比例(0.4-0.8):
- GCN性能显著下降(3.1%-9.2%)
- LAGCN性能下降幅度较小(2.9%-6.0%)
- LAGCN在信息缺失时表现出更强的鲁棒性
- 性能差距扩大:
- 随着屏蔽比例增加,LAGCN相比GCN的优势更加明显
- 证明了局部增强能够有效补充缺失的特征信息
表7. 在Pubmed数据集上案例研究的GCN和LAGCN结果总结(分类准确率%)
| 节点度 | [2, 5] | [6, 20] |
|---|---|---|
| #Nodes | 761 | 189 |
| GCN | 78.2 | 82.0 |
| LAGCN | 79.9 | 82.2 |
| ∆ | 1.7 | 0.2 |
案例研究分析:
- 节点分布:
- 低度节点(度2-5):761个节点,占80.1%
- 高度节点(度6-20):189个节点,占19.9%
- 性能提升模式:
- 低度节点:LAGCN相比GCN提升1.7%(78.2%→79.9%)
- 高度节点:LAGCN相比GCN提升0.2%(82.0%→82.2%)
- 关键洞察:
- 局部增强对低度节点的帮助更大
- 低度节点信息传播受限,局部增强提供了额外的邻域信息
- 高度节点本身已有丰富信息,提升空间有限
表8. 在Cora数据集上LAGCN与GCN的MADgap指标(10次运行)
| 层数 | GCN | LAGCN |
|---|---|---|
| Layer2 | 0.63±0.02 | 0.68±0.02 |
| Layer3 | 0.61±0.08 | 0.61±0.07 |
| Layer4 | 0.55±0.06 | 0.64±0.05 |
| Layer5 | 0.39±0.23 | 0.61±0.06 |
| Layer6 | 0.24±0.47 | 0.31±0.17 |
过平滑分析:
- 浅层(2-3层):
- LAGCN的MADgap指标与GCN相当或略高
- 表明局部增强在浅层保持了良好的局部性
- 中层(4-5层):
- LAGCN的MADgap指标明显高于GCN
- 特别是在第5层:LAGCN (0.61) vs GCN (0.39)
- 深层(6层):
- 两者都出现明显的过平滑现象
- 但LAGCN仍然保持相对较高的MADgap值
- 关键发现:
- LAGCN能够更好地保持节点表示的局部性
- 通过丰富局部信息,间接缓解了过平滑问题
- 在深层网络中,LAGCN的表示质量仍然优于GCN
综合结论:
- 局部增强是性能提升的主要来源(1.8%的贡献)
- 对信息缺失具有强鲁棒性,特别是在高屏蔽比例下
- 特别有助于低度节点,为其提供额外的邻域信息
- 能够缓解过平滑问题,保持节点表示的局部性
- 各组件协同工作,共同提升模型性能
4.4. 消融研究
为了证明我们提出的局部增强模型的有效性,我们在Pubmed数据集上对LAGCN进行了实验,将其与几个消融变体进行比较。结果如表5所示。
消融研究结果:
- “+ concatenation”:我们只应用第3.3节中LAGCN的拼接式设计架构,将原始特征矩阵作为额外的拼接输入。改进为0.3%,这表明我们对架构的修改对结果没有很大影响。
- “+ local augmentation”:我们使用生成的特征矩阵作为额外的拼接输入,但不使用一致性训练。虽然我们没有使用一致性训练,但生成的特征矩阵作为额外输入将GCN的测试准确率提高了1.8%。
- 完整LA方法:通过一致性训练和锐化技巧,我们可以进一步提升性能。
关键洞察:
从消融研究中可以明显看出,性能提升主要归因于我们提出的生成式局部增强框架:
- 架构修改的贡献:仅0.3%的改进
- 局部增强的贡献:1.8%的改进
- 一致性训练的贡献:额外的性能提升
这证明了:
- 局部增强是性能提升的主要来源
- 生成的特征向量确实提供了有价值的信息
- 一致性训练进一步稳定和提升了模型性能
- 我们的方法在保持模型简洁性的同时实现了显著的性能改进
这些结果验证了局部增强框架各个组件的有效性,并证明了该方法的核心价值在于生成高质量的局部增强特征。
4.5. 对缺失信息的鲁棒性
在本节中,我们进行实验来验证我们提出的框架对特征属性中缺失信息具有鲁棒性。具体地,我们屏蔽每个特征向量的一定百分比的属性,并使用相同的管道对屏蔽的特征矩阵进行增强。如表6所示,我们可以看到,随着屏蔽比例的增加,在Citeseer数据集中,GCN和LA-GCN之间的性能差距在大多数情况下都会扩大,这证实了我们的洞察:我们的局部增强可以补充局部邻域的上下文信息。
主要发现:
- 鲁棒性验证:
- 随着特征屏蔽比例增加,LA-GCN相比GCN的优势更加明显
- 证明了局部增强方法能够有效处理不完整的特征信息
- 上下文信息补充:
- 局部增强能够从邻域信息中推断和补充缺失的特征
- 在信息缺失的情况下,增强方法显示出更强的适应性
4.6. 案例研究
在本节中,我们探索应用我们的局部增强方法后不同节点测试准确率的变化。注意,我们只应用局部增强而不使用一致性训练,并将S设置为1。结果总结在表7中。
主要结论:
- 节点度分布:
- Pubmed测试集中大多数节点的度相对较小
- 度小于6的节点约占76.1%
- 性能提升模式:
- 度较小的节点往往具有较低的测试准确率
- 我们的局部增强可以为这些节点丰富局部信息,从而提升它们的性能
- 局部信息增强:
- 对于低度节点,局部增强提供了额外的邻域信息
- 这有助于改善信息传播受限节点的表示质量
4.7. 过平滑分析
众所周知,堆叠GNN层会导致过平滑(Li et al., 2018)。在本节中,我们讨论我们提出的方法如何与现有方法相比防止GNN中的过平滑问题。我们利用MADgap(Chen et al., 2020a)指标来比较我们的方法与现有GNNs。
主要发现:
- MADgap指标比较:
- 表8报告了LAGCN和GCN在Cora数据集上(不同层数)的MADgap指标
- 可以观察到,LAGCN的MADgap指标在不同层上都大于或等于GCN
- 过平滑缓解机制:
- 虽然我们的方法不是专门解决过平滑问题的
- 但我们的方法可以丰富局部邻域信息,从而改善节点表示的局部性
- 因此,我们可以缓解过平滑问题
- 局部性保持:
- 局部增强通过提供额外的局部信息,帮助保持节点表示的局部特征
- 这有助于防止深层GNN中的表示过度平滑
关键洞察:
- 信息补充能力:局部增强方法在特征信息缺失时表现出更强的鲁棒性
- 低度节点优化:方法特别有助于改善信息传播受限的低度节点
- 过平滑缓解:通过丰富局部信息,间接缓解了深层GNN的过平滑问题
- 通用性验证:这些分析证明了局部增强方法在不同场景下的有效性和适应性
这些实验从多个角度验证了局部增强方法的有效性和鲁棒性,为方法的实际应用提供了坚实的理论基础。
5. 相关工作
5.1. 图上的无监督表示学习
一般来说,图上的无监督表示学习方法包括基于对比的自监督方法(Velickovic et al., 2019; Sun et al., 2020; Hassani & Khasahmadi, 2020; You et al., 2020)、图嵌入方法(García-Durán & Niepert, 2017; Hamilton et al., 2017)和随机游走方法(Perozzi et al., 2014; Tang et al., 2015; Grover & Leskovec, 2016)。
对比学习方法(Hassani & Khasahmadi, 2020; You et al., 2020)采用对比损失函数来强制最小化正样本对的表示距离,最大化负样本对的距离。
随机游走方法通过在节点间进行随机游走来获得句子,并使用NLP词嵌入模型来学习节点表示。
我们的局部增强也是一种学习局部邻域信息的无监督方法。
5.2. 图生成模型
生成模型(Goodfellow et al., 2014; Kingma & Welling, 2013)是通过无监督学习学习数据分布的强大工具。最近,研究人员提出了几种有趣的图数据生成生成模型。
- 变分图自编码器(VGAE)(Kipf & Welling, 2016)利用潜在变量来学习无向图的可解释表示
- Salha et al. (2019) 使用简单的线性模型替换VGAE中的GCN编码器,降低编码方案的复杂度
- Xu et al. (2019a) 提出了生成GCN模型来学习增长图的节点表示
- ConDgen(Yang et al., 2019)利用GCN编码器处理条件结构生成的不变排列
此外,一些方法被提出将图生成模型应用于各种应用中,如图匹配(Simonovsky & Komodakis, 2018)、分子设计(Liu et al., 2018)、逆合成预测(Shi et al., 2020)和化学设计(Samanta et al., 2018)。
与这些主要关注结构生成的方法相比,我们的模型充分利用了生成模型的力量进行特征表示生成,可以作为下游骨干模型的增强技术。
5.3. 拼接式设计
在这项工作中,我们使用拼接来连接原始特征和每个训练迭代中不同的生成特征,通过局部增强来丰富邻域信息。拼接式设计是一种通用技术,许多工作都采用这种方法,如GAT(Veličković et al., 2018)和SIGN(Rossi et al., 2020)。
SIGN专注于大型图上GNN模型的可扩展训练,通过邻接矩阵的幂次来增强多跳信息的特征。
6. 结论
我们提出了局部增强,这是一种新技术,利用生成模型来学习给定中心节点特征的中心节点邻居特征的条件分布。我们将来自训练良好的生成模型的生成特征矩阵输入到一些修改的骨干GNN模型中,以增强它们的性能。
主要贡献:
- 性能提升:实验表明,我们的模型可以在各种GNN架构和基准数据集上提高性能
- 最先进结果:我们的模型在各种半监督节点分类任务上取得了新的最先进结果
- 通用性:方法适用于不同的GNN架构和数据集
局限性:
我们提出的框架的一个局限性是我们没有利用2跳邻居或使用随机游走来为中心节点找到更多相关邻居。
未来工作:
一个未来的工作是如果中心节点的度较小,提取更多2/3跳邻居;如果图很大,学习随机采样节点的条件分布。
致谢
我们感谢所有审稿人的有益评论和建议,感谢腾讯AI实验室的支持以及Yulai Cong的有益讨论。特别地,Songtao Liu也感谢Hao Yin的鼓励。Liu和Wu得到了NSF资助CNS-1652790和宾夕法尼亚州立大学安全研究与教育中心(CSRE)种子资助的部分支持。
总结:
这篇论文提出了一个创新的局部增强框架,通过生成模型学习邻域特征的条件分布来增强GNN的性能。该方法在多个数据集和任务上都取得了显著的性能提升,为图神经网络的发展提供了新的思路。